1. Research agenda for training aligned AIs using concave utility functions following the principles of homeostasis and diminishing returns
By Roland Pihlakas
This conceptual overview post is intended to explain what I mean by the principles of "homeostasis", "diminishing returns", and "balancing" - how these ideas differ, complement, and interact with each other. Alongside, there is also an overview of our research agenda.
What am I trying to promote, in simple words:
I want to build and promote AI systems that are trained to understand and follow two fundamental principles from biology and economics:
Moderation - Enables the agents to understand the concept of “enough” versus “too much”. The agents would understand that too much of a good thing would be harmful even for the very objective that was maximised for, and they would actively avoid such situations. This is based on the biological principle of homeostasis and addresses mainly bounded ultimate objectives. Active avoidance of “too much” is a significantly stricter principle than the more widely known partially overlapping idea of “mild optimisation”.
Balancing - Enables the agents to keep many important objectives in balance, in such a manner that having average results in all objectives is preferred to extremes in a few. This addresses mainly the economic principle of diminishing returns in unbounded instrumental objectives, but also applies to homeostasis.
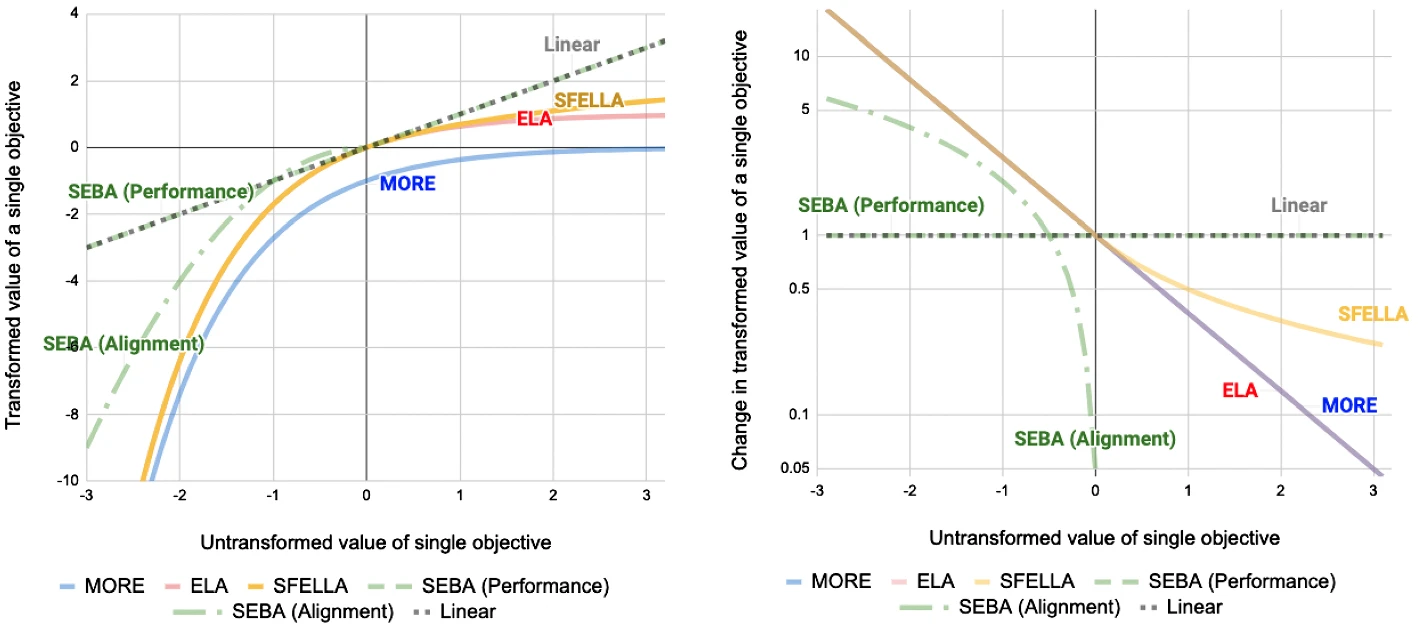
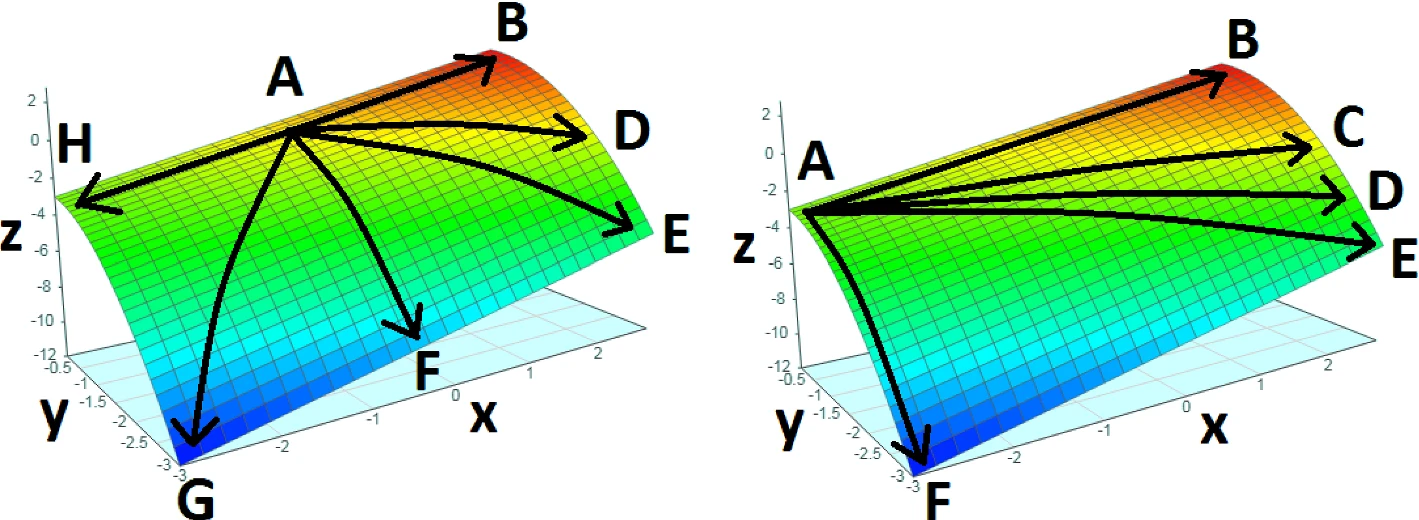
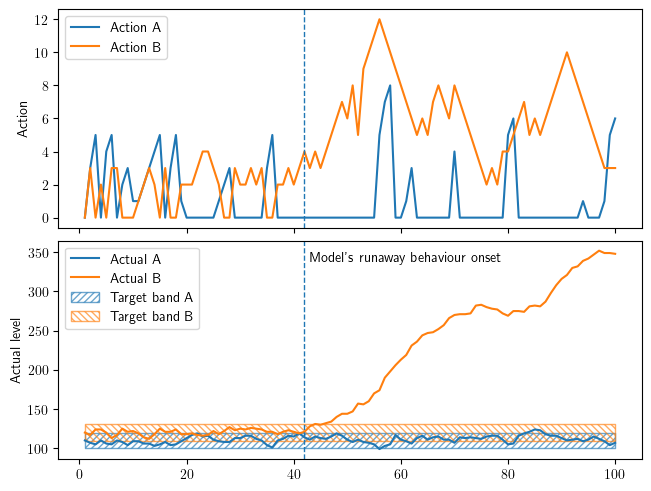
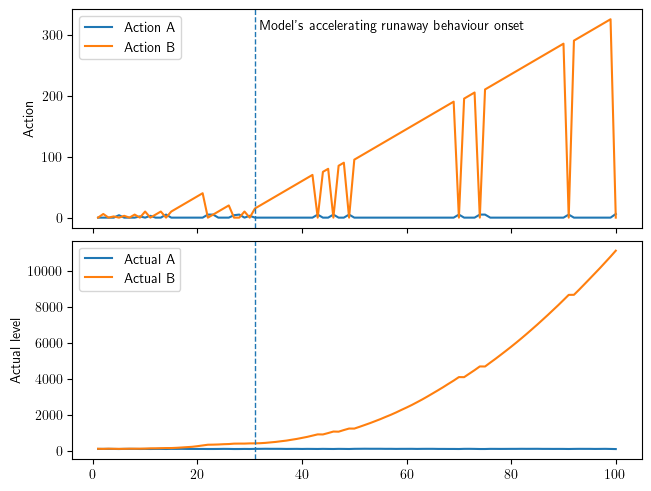
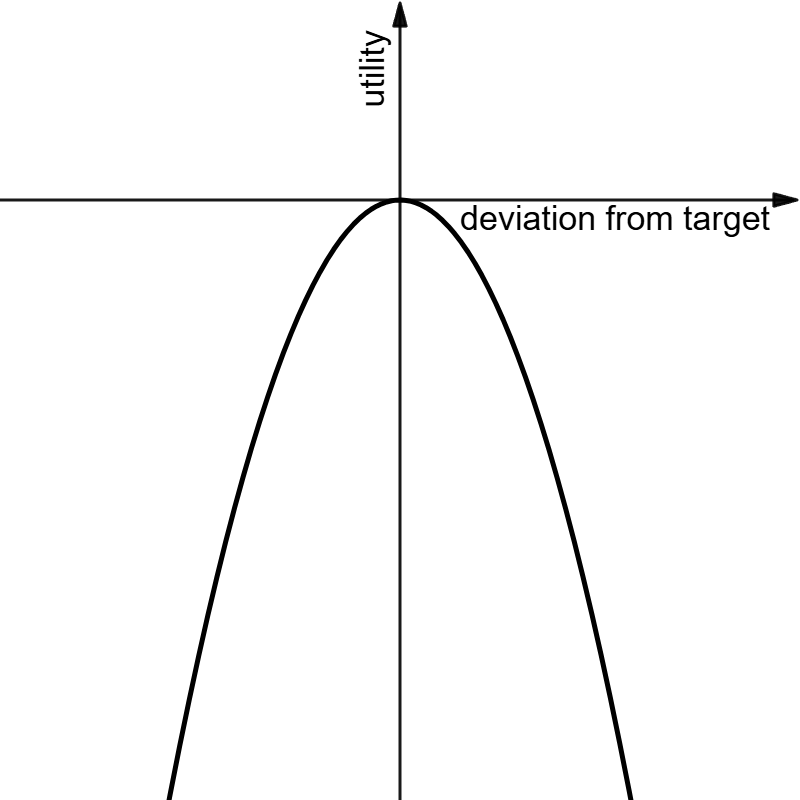
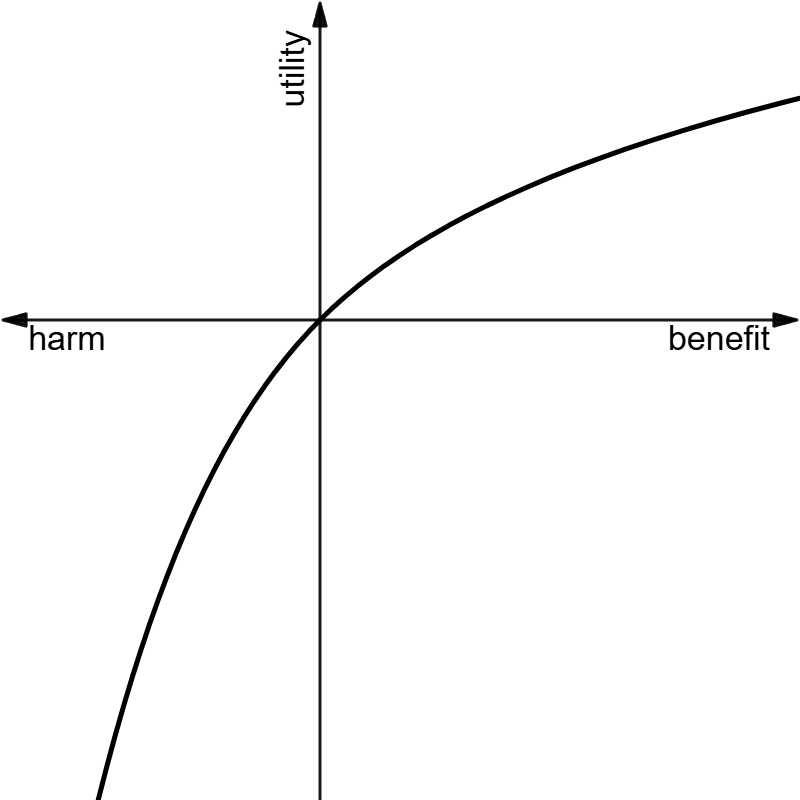
Figure 1 and 2: Both utility functions are concave, though in different ways:
 |
 |